HA кластер
Часть 1: Heartbeat
Кластер - это прежде всего система повышенной готовности (high
availability - HA), построеная с учетом того, что она продолжает
работать безотказно, даже если какая-то ее часть выходит из строя.
Heartbeat - продукт проекта Linux-HA, позволяющий реализовать механизм
безотказной работы отдельных частей кластера. Первый, кому необходим
этот механизм в кластере - это распределитель нагрузки (load balancer,
или director).
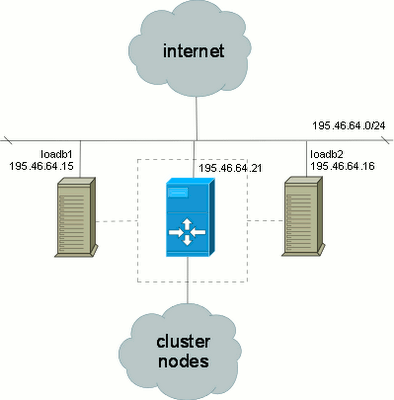
Допустим, у нас есть два сервера (loadb1, loadb2), которые выделены
для того, чтобы стать распределителями нагрузки в будущем кластере. Но
прежде чем устанавливать на них программное обеспечение для управление
кластером, необходимо настроить и оттестировать механим безотказной
работы - когда какой-либо из серверов (loadb1 или loadb2) выходит из
строя, второй, благодаря heartbeat, заменяет его. В данном случае
условием того, что сервер вышел из строя будет считаться, что он не
отвечает на broadcast запросы, т.е. проблемы в сетевом интерфейсе.
Сервера loadb1 и loadb2 будут эмулировать ip-адрес кластера -
195.46.64.21, т.е. он будет "поднят" на сетевом интерфейсе как
дополнительный (alias).
 Настройка heartbeat в Debian 4.0 (Etch)
1. Установить пакет heartbeat-2 и все зависимости, которые он за собой
тянет.
apt-get install heartbeat-2
В конце установки сервис heartbeat не сможет запуститься, потому как
не созданы основные конфигурационные файлы - ha.cf, authkeys,
haresources.
ha.cf - основной конфигурационный файл, содержащий массу различных
параметров того, как будет осуществляться heartbeat-механизм. За
основу можно взять файл, идущий в пакете (расположен в
/usr/share/doc/heartbeat-2). Перед использованием достаточно
установить 3 параметра (директивы):
bcast eth0
node loadb1
node loadb2
Указав таким образом использовать heartbeat-механизм через eth0
интерфейсы на основе broadcast-запросов. Имена loadb1, loadb2 должны
быть hostname-именами серверов, команда uname -a должна возвращать
такие же значения.
authkeys - файл для взаимной аутентификации серверов loadb1 и loadb2.
Можно использовать sha, md5, но чтобы не расходовать ресурсы
достаточно использовать crc. После создания файл, необходимо
установить права доступа к нему только для root
# cat > authkeys
auth 1
1 crc
[Ctrl+C]
# chmod 600 authkeys
haresources - файл, описывающий ресурсы, контролируемые серверами
loadb1 и loadb2. Ресурсы представляют собой обычные стоп/старт
скрипты, похожие чем-то на сценарии из/etc/init.d. В директории
/etc/ha.d/resource.d можно посмотреть доступные (уже готовые к
использованию) сценарии. В данном примере будет использован ресурс
IPaddr для активации дополнительного ip-адреса на интерфейсе eth0.
loadb1 IPaddr::195.46.64.21/24/eth0
Данные конфигурационные файлы должны быть помещены на обоих серверах в
директорию /etc/ha.d и должны быть идентичны. После того, как все
подготовлено, запустить heartbeat-сервис на обоих серверах:
# /etc/init.d/heartbeat start
Starting High-Availability services:
2007/06/28_10:14:21 INFO: IPaddr Resource is stopped
Done.
Спустя пару секунд на сервере loadb1 будет поднят дополнительный
ip-адрес - 195.46.64.21.
loadb1# ifconfig
eth0 Link encap:Ethernet HWaddr 00:60:08:04:09:0D
inet addr:195.46.64.15 Bcast:195.46.64.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:1119456 errors:0 dropped:0 overruns:0 frame:0
TX packets:96462 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:79824340 (76.1 MiB) TX bytes:18991729 (18.1 MiB)
Interrupt:10 Base address:0xe000
eth0:0 Link encap:Ethernet HWaddr 00:60:08:04:09:0D
inet addr:195.46.64.21 Bcast:195.46.64.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Interrupt:10 Base address:0xe000
Если что-то случается с loadb1 (можно сэмулировать аварию, отправив
его на перезагрузку), loadb2 поднимает данный ip-адрес на своем eth0
интерфейсе и принимает на себя основную роль.
loadb2# ifconfig
eth0 Link encap:Ethernet HWaddr 00:10:5A:BF:2B:8C
inet addr:195.46.64.16 Bcast:195.46.64.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:1256304 errors:0 dropped:0 overruns:0 frame:0
TX packets:93726 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:99944699 (95.3 MiB) TX bytes:19336953 (18.4 MiB)
Interrupt:9 Base address:0xec00
eth0:0 Link encap:Ethernet HWaddr 00:10:5A:BF:2B:8C
inet addr:195.46.64.21 Bcast:195.46.64.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Interrupt:9 Base address:0xec00
В /var/log/messages можно проследить происходящее - всё очень подробно
и понятно.
Ссылки:
1. Программное обеспечение повышенной готовности промежуточного
уровня в Linux, часть 1: Heartbeat и Web-сервер Apache
http://www.ibm.com/developerworks/ru/linux/library/l-halinux/
2. How To Set Up A Loadbalanced High-Availability Apache Cluster
http://howtoforge.com/high_availability_loadbalanced_apache_cluster
3. The High Availability Linux Project
http://www.linux-ha.org/
Часть 2: Storage
Для функционирования кластерной системы, необходимо наличие единой
дисковой подсистемы, доступной для всех серверов (node), работающих
внутри кластера.
С дисковой подсистемой (storage) можно общаться на уровне:
- сервиса (примеры - NFS-директория, примонтированная на всех нодах, DNBD)
- блочного устройства, доступного всем нодам (SAN)
Самым простым решением является использование сетевой файловой системы
NFS. В данном случае все проблемы по обслуживанию блокировок при
совместной работе с данными NFS-служба берет на себя. Статья [1]
прекрасно описывает пример создания storage на основе NFS. Я
попробовал на Debian 4.0 - все отлично работает. Но присутствие уровня
сервиса накладывает некоторый отрицательный отпечаток на
производительность.
Более низкий уровень общения с дисковой системой - уровень обычного
блочного устройства (block device). В этом случае Вы имете в системе
дополнительный диск (/dev/sdb, /dev/hdb), с которым работаете как с
обычным жестким диском, но есть несколько "но":
* если данный диск доступен нескольким нодам в режиме записи (RW),
Вы должны обеспечить на нем функционирование кластерной файловой
системы, которая позволит работать одновременно с одними и теми же
данными с разных нодов.
* Вам придется раскошелиться на приобретение SAN (на основе Fibre
Channel или более дешевого - iSCSI. Точных цен я не знаю, но
это недешевая покупка :)
Перед написанием этих строк я попробовал две кластерные файловые
системы - GFS и OCFS2. Если сравнивать "на глаз" производительность,
то можно сказать, что обе файловые системы работают более менее
одинакого быстро. Но GFS по сравнению с OCFS на первых порах более
сложен в запуске, так как требует установки и настройки Red Hat
Cluster Suite. Данный Suite включает в себя все необходимые "примочки"
для работы кластера, начиная от heartbeat'а, поддержки множества
сетевых служб, заканчивая фенсингом кластерной файловой системы
(fencing). Информации по GFS доступно достаточно, чего не скажешь
об OCSF. Обе данные кластерные файловые системы опробованы на CentOS
5, все работает стабильно без каких-либо оговорок, лог действий скоро
выложу.
Ссылки:
1. Setting Up A Highly Available NFS Server
http://howtoforge.com/high_availability_nfs_drbd_heartbeat
2. Distributed filesystem for Debian clusters? (discussion)
http://www.debian-administration.org/articles/348
3. DRBD/NFS: Linux HA
http://linux-ha.org/DRBD/NFS
Настройка heartbeat в Debian 4.0 (Etch)
1. Установить пакет heartbeat-2 и все зависимости, которые он за собой
тянет.
apt-get install heartbeat-2
В конце установки сервис heartbeat не сможет запуститься, потому как
не созданы основные конфигурационные файлы - ha.cf, authkeys,
haresources.
ha.cf - основной конфигурационный файл, содержащий массу различных
параметров того, как будет осуществляться heartbeat-механизм. За
основу можно взять файл, идущий в пакете (расположен в
/usr/share/doc/heartbeat-2). Перед использованием достаточно
установить 3 параметра (директивы):
bcast eth0
node loadb1
node loadb2
Указав таким образом использовать heartbeat-механизм через eth0
интерфейсы на основе broadcast-запросов. Имена loadb1, loadb2 должны
быть hostname-именами серверов, команда uname -a должна возвращать
такие же значения.
authkeys - файл для взаимной аутентификации серверов loadb1 и loadb2.
Можно использовать sha, md5, но чтобы не расходовать ресурсы
достаточно использовать crc. После создания файл, необходимо
установить права доступа к нему только для root
# cat > authkeys
auth 1
1 crc
[Ctrl+C]
# chmod 600 authkeys
haresources - файл, описывающий ресурсы, контролируемые серверами
loadb1 и loadb2. Ресурсы представляют собой обычные стоп/старт
скрипты, похожие чем-то на сценарии из/etc/init.d. В директории
/etc/ha.d/resource.d можно посмотреть доступные (уже готовые к
использованию) сценарии. В данном примере будет использован ресурс
IPaddr для активации дополнительного ip-адреса на интерфейсе eth0.
loadb1 IPaddr::195.46.64.21/24/eth0
Данные конфигурационные файлы должны быть помещены на обоих серверах в
директорию /etc/ha.d и должны быть идентичны. После того, как все
подготовлено, запустить heartbeat-сервис на обоих серверах:
# /etc/init.d/heartbeat start
Starting High-Availability services:
2007/06/28_10:14:21 INFO: IPaddr Resource is stopped
Done.
Спустя пару секунд на сервере loadb1 будет поднят дополнительный
ip-адрес - 195.46.64.21.
loadb1# ifconfig
eth0 Link encap:Ethernet HWaddr 00:60:08:04:09:0D
inet addr:195.46.64.15 Bcast:195.46.64.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:1119456 errors:0 dropped:0 overruns:0 frame:0
TX packets:96462 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:79824340 (76.1 MiB) TX bytes:18991729 (18.1 MiB)
Interrupt:10 Base address:0xe000
eth0:0 Link encap:Ethernet HWaddr 00:60:08:04:09:0D
inet addr:195.46.64.21 Bcast:195.46.64.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Interrupt:10 Base address:0xe000
Если что-то случается с loadb1 (можно сэмулировать аварию, отправив
его на перезагрузку), loadb2 поднимает данный ip-адрес на своем eth0
интерфейсе и принимает на себя основную роль.
loadb2# ifconfig
eth0 Link encap:Ethernet HWaddr 00:10:5A:BF:2B:8C
inet addr:195.46.64.16 Bcast:195.46.64.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:1256304 errors:0 dropped:0 overruns:0 frame:0
TX packets:93726 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:99944699 (95.3 MiB) TX bytes:19336953 (18.4 MiB)
Interrupt:9 Base address:0xec00
eth0:0 Link encap:Ethernet HWaddr 00:10:5A:BF:2B:8C
inet addr:195.46.64.21 Bcast:195.46.64.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Interrupt:9 Base address:0xec00
В /var/log/messages можно проследить происходящее - всё очень подробно
и понятно.
Ссылки:
1. Программное обеспечение повышенной готовности промежуточного
уровня в Linux, часть 1: Heartbeat и Web-сервер Apache
http://www.ibm.com/developerworks/ru/linux/library/l-halinux/
2. How To Set Up A Loadbalanced High-Availability Apache Cluster
http://howtoforge.com/high_availability_loadbalanced_apache_cluster
3. The High Availability Linux Project
http://www.linux-ha.org/
Часть 2: Storage
Для функционирования кластерной системы, необходимо наличие единой
дисковой подсистемы, доступной для всех серверов (node), работающих
внутри кластера.
С дисковой подсистемой (storage) можно общаться на уровне:
- сервиса (примеры - NFS-директория, примонтированная на всех нодах, DNBD)
- блочного устройства, доступного всем нодам (SAN)
Самым простым решением является использование сетевой файловой системы
NFS. В данном случае все проблемы по обслуживанию блокировок при
совместной работе с данными NFS-служба берет на себя. Статья [1]
прекрасно описывает пример создания storage на основе NFS. Я
попробовал на Debian 4.0 - все отлично работает. Но присутствие уровня
сервиса накладывает некоторый отрицательный отпечаток на
производительность.
Более низкий уровень общения с дисковой системой - уровень обычного
блочного устройства (block device). В этом случае Вы имете в системе
дополнительный диск (/dev/sdb, /dev/hdb), с которым работаете как с
обычным жестким диском, но есть несколько "но":
* если данный диск доступен нескольким нодам в режиме записи (RW),
Вы должны обеспечить на нем функционирование кластерной файловой
системы, которая позволит работать одновременно с одними и теми же
данными с разных нодов.
* Вам придется раскошелиться на приобретение SAN (на основе Fibre
Channel или более дешевого - iSCSI. Точных цен я не знаю, но
это недешевая покупка :)
Перед написанием этих строк я попробовал две кластерные файловые
системы - GFS и OCFS2. Если сравнивать "на глаз" производительность,
то можно сказать, что обе файловые системы работают более менее
одинакого быстро. Но GFS по сравнению с OCFS на первых порах более
сложен в запуске, так как требует установки и настройки Red Hat
Cluster Suite. Данный Suite включает в себя все необходимые "примочки"
для работы кластера, начиная от heartbeat'а, поддержки множества
сетевых служб, заканчивая фенсингом кластерной файловой системы
(fencing). Информации по GFS доступно достаточно, чего не скажешь
об OCSF. Обе данные кластерные файловые системы опробованы на CentOS
5, все работает стабильно без каких-либо оговорок, лог действий скоро
выложу.
Ссылки:
1. Setting Up A Highly Available NFS Server
http://howtoforge.com/high_availability_nfs_drbd_heartbeat
2. Distributed filesystem for Debian clusters? (discussion)
http://www.debian-administration.org/articles/348
3. DRBD/NFS: Linux HA
http://linux-ha.org/DRBD/NFS